堆在一起

Day 618
事情往往都堆在一起。
霁风这边,近来大家对面条强势霸道的做法感到十分不满,首先在财务制度上,他选择了一个他相熟的人来掌管财务,而大家的想法是推选家明的太太负责。其实他有自己的想法没有问题,可以进行公开的投票嘛。但是,他的做法却是在股东会议上直接把那个人带了过来,直接把象征财务印章的ukey当场甩给了这个人,大家都很错愕,场面尴尬。最终还是搁置了财务制度的讨论,保持现状。除了财务这件事,在业务方面,一些核心的关键节点如:商务谈判细节、商务接洽预算、分成比例、合同细节等,都不透明。之前我们都以为林医生和面条一起负责,但是林医生却跟我和家明大吐苦水,所有关键节点的决策权都不在他,甚至商量的余地也没有。按照这两件事情来看,未来的趋势,我们的身份极有可能是换了一家公司打工而已,这当然不是我们所想的状态。目前的现状是整个团队的凝聚力受到了很大的挑战,面条委派的所谓律师,在群里发起了周末的股东例会,大家都没有任何响应。我打算晚一些回复:等家明回来再议,因为家明目前正在休假。
公司这边,感觉到新来的品质经理依旧配合度一般,所以我带着他一起找到老板,当面澄清了我和新来的品质经理的定位问题,老板也再次强调,以我为主。希望这样能让他的配合度有所提升吧。 这些琐事着实让我沮丧,但也有喜悦——最近公共技术组在技术上有了突破,和从字节过来的新人一起,终于把精准测试服务的技术框架确定下来了,很给力。一路走来,着实不易。本来是做基于机器学习的缺陷预测,但是遇到数据特征工程的难题,我们公司的数据太零散且混乱了,根本无法对样本做有效的标记。调整方案,从有监督学习改成无监督学习,但是聚类的结果却更混乱。最终思佳(新人)凭借自己优秀的外语阅读能力(新南威尔士毕业,英特尔实习1年,字节工作1年),找到了一篇学术论文,有了一个崭新的思路:基于BP神经网络的模型训练。
大致的步骤是:
获得代码语句覆盖和测试用例的关系,列出矩阵图(向量是用例的执行结果)
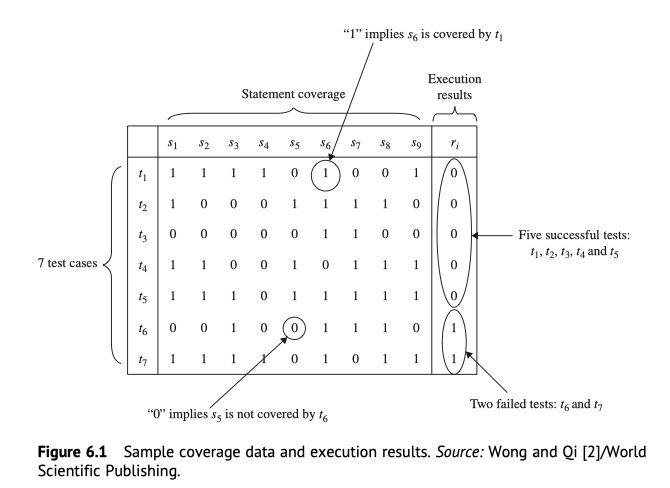
将向量值输入到BP神经网络,开始训练,输出对应的测试用例
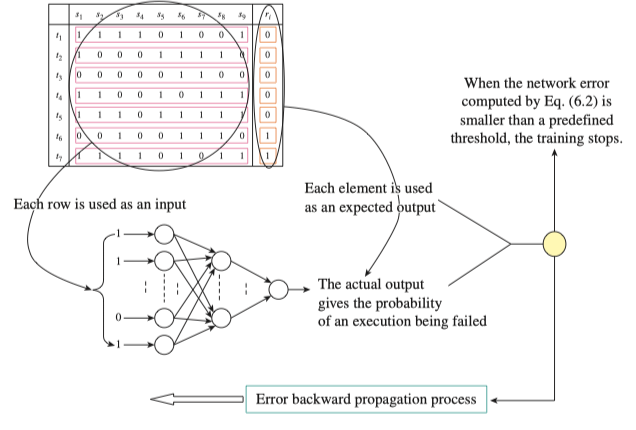
使用BP神经网络评估每条语句出现缺陷的概率
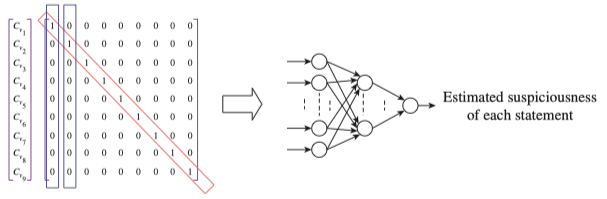
以上方法输出为每条语句的bug概率,但事实上缺陷不一定存在于概率最大的语句中,按照概率从大到小排序之后进行评估可能会耗费一部分时间,所以对此进行改进。 思想:缺陷应当被所有失败的测试用例覆盖 -> 与缺陷相关的语句被所有失败用例覆盖(在此处缩小范围,只考虑失败用例的语句覆盖情况)
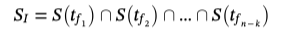
最后,整体过程如下: 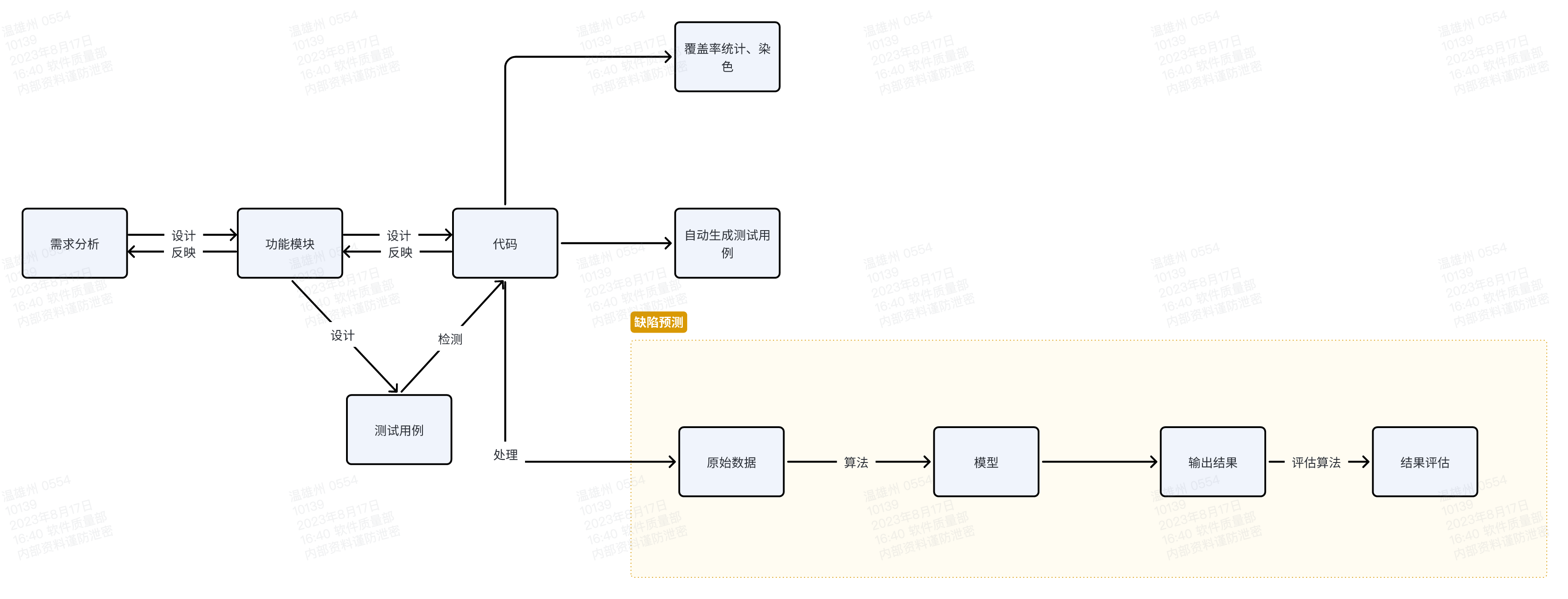 整体流程示意
整体流程示意